
: A Powerful New Web Accessibility Feature Demands Judicious Implementation")



The digital information landscape is undergoing a profound transformation with the ascendancy of conversational AI search engines, a development highlighted by Fast Company in February 2024. These innovative platforms, powered by sophisticated large language models (LLMs), represent a paradigm shift from traditional keyword-based search. Instead of merely presenting a list of links, they are engineered to directly answer user queries by retrieving, synthesizing, and summarizing information gleaned from vast swathes of the Internet. This emergent technology has sparked considerable enthusiasm and a wave of experimentation within academic, scientific, and commercial sectors, offering a compelling alternative to the long-established Google model of information retrieval.
A New Era of Information Retrieval: From Keywords to Conversations
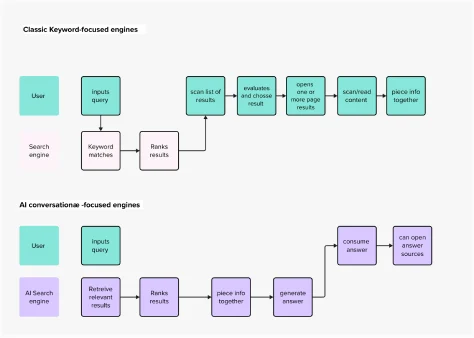
The evolution of search has been a continuous journey, beginning with rudimentary web directories and progressing to the highly sophisticated algorithmic indexing championed by Google. For decades, users have been conditioned to a mental model where searching involves crafting precise keywords, sifting through pages of results, and then navigating to external websites to find their answers. This established user experience, while effective, often demands significant cognitive effort, requiring users to evaluate the relevance and credibility of multiple sources.
The advent of generative AI, particularly with the widespread adoption of tools like ChatGPT, has introduced a new user interface paradigm: the conversational chatbot. This interface, characterized by natural language interaction and direct responses, has fundamentally altered user expectations for digital tools. Conversational AI search engines embody this shift, proposing a more intuitive, human-like interaction with information. Companies like Perplexity AI and Andi are at the forefront of this innovation, showcasing distinct approaches to integrating generative AI into the search experience.
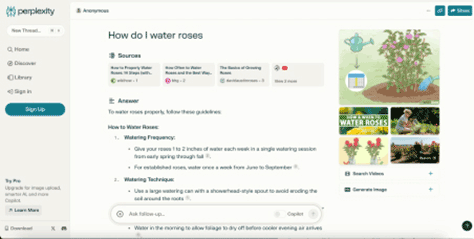
Perplexity AI, for instance, presents a familiar layout with an input field and a results area, yet its underlying mental model is distinctly conversational. As depicted in early observations, its home page integrates traditional search elements with a generative AI core. Upon querying, Perplexity doesn’t just list links; it constructs a concise, formatted answer by collating and summarizing snippets from various online sources, presenting the information directly to the user. This direct answer format dramatically reduces the user’s cognitive load, circumventing the need to click through multiple links and manually synthesize information.
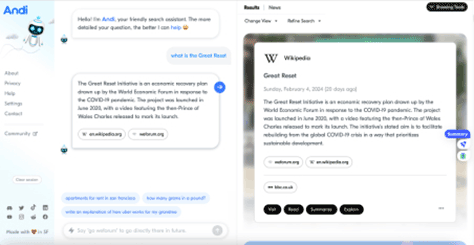
Andi takes this conversational approach further in its user interface design, prioritizing a chatbot-like layout. While its visual presentation leans heavily into the conversational model, its information architecture, as further discussed, often retains elements more akin to classic search, emphasizing the source documents alongside a concise answer. These examples represent a "technology push" innovation, where the availability of powerful new technologies like generative AI drives market evolution, rather than a direct response to a pre-existing, unmet user need. The long-term success and user benefit of such technology-driven evolution remain subjects of ongoing observation and analysis.
Enhancing Usability: Streamlining the Search Journey
Conversational AI search engines offer clear improvements in usability and interaction design, particularly by aligning with fundamental usability heuristics. The direct answer format, exemplified by Perplexity, mirrors the natural Q&A pattern of human conversation, making the interaction feel more intuitive and efficient. This design choice directly addresses several of Nielsen’s usability heuristics for user-interface design, including:
- Match between system and the real world: By providing direct, conversational answers, these systems align more closely with how humans naturally seek and exchange information.
- Flexibility and efficiency of use: Experienced users can obtain answers more rapidly, while novices find the system easier to grasp due to its intuitive conversational nature.
- Error prevention: By synthesizing information and presenting a direct answer, the system reduces the likelihood of users misinterpreting search results or failing to find relevant information amidst a sea of links.
- Recognition rather than recall: Users recognize answers rather than having to recall or infer them from a list of links.
The most significant usability enhancement lies in eliminating the intermediate steps of evaluating individual search results, making educated guesses about content, opening new pages, and scanning text. The user’s ultimate goal – finding an answer within a text – is achieved more directly and with less effort. This streamlined journey significantly improves the user experience, particularly for queries requiring factual recall or quick summaries.
Broader Implications: Trust, Explainability, and the Future of Critical Thinking
While the usability benefits are evident, the rise of conversational AI search engines introduces profound implications concerning trust, AI explainability, and the potential impact on human agency and critical thinking. When using platforms like Perplexity, users implicitly delegate a substantial degree of decision-making to the AI. The generative technology selects, extracts, and summarizes content, effectively acting as an intelligent intermediary. However, these applications often fall short in communicating why specific sources were chosen over others, or how the summary was constructed. This lack of transparency directly conflicts with the crucial aspect of AI explainability (XAI), which is vital for fostering user trust.
Francesca Rossi, IBM’s Global Ethics Leader, emphasizes that AI’s ability to make important decisions, its alignment with human values, and its capacity to explain its reasoning are central to building trust. In an enterprise context, the risks associated with untrustworthy AI—including regulatory fines, reputational damage, and legal suits—are pressing concerns. However, for individual "Internauts" (highly skilled, habitual internet users), the immediate consequences of uncritically accepting AI-generated information may seem less severe, yet the long-term societal implications are substantial.
Roberta Katz’s architectural analogy, "first you make the building and then the building makes you," provides a poignant lens through which to view the impact of digital interfaces. Just as physical environments shape human behavior, the architecture of our apps and IT systems profoundly influences their users. It is a reasonable hypothesis that the convenience of ready-made, authoritative-sounding answers from AI search engines could lead users to become accustomed to accepting information without critical scrutiny regarding its accuracy, bias, or veridicity.
While these tools typically provide links to source documents, several critical questions remain unanswered for the user:
- Which sources were prioritized, and why?
- How were conflicting accounts or perspectives handled in the summarization process?
- Was the information presented neutrally, or does it reflect inherent biases in the training data or the LLM’s design?
These issues extend beyond the typical challenges of traditional search engines, stemming from the deeper delegation of decision-making inherent in generative AI. Even with full explainability, the ease of access to synthesized information could potentially erode users’ critical thinking skills over time, much like how text messaging has been argued to contribute to less formal writing. The cognitive exercise of sifting through Google’s SERP, comparing information from different articles, and patiently piecing together answers, while more tedious, actively engages analytical and creative faculties, potentially fostering a more critical engagement with information.
If the prevailing mental model of a search engine transforms into that of an infallible oracle that always provides the "right" answer, the consequences for our ability to discern truth from falsehood could be immense. While this might be negligible for trivial queries (e.g., finding a new pair of trousers), it becomes critically important for domains like policymaking, scientific research, journalism, or civil discourse, where accuracy, nuance, and diverse perspectives are paramount.
Not all AI search experiences are designed identically. Andi, for example, while adopting a chatbot-like UI, maintains an information architecture that encourages engagement with source documents. In its search results, the brief answer is often a direct snippet from a primary source (like Wikipedia), with a prominent list of all relevant sources and their links displayed alongside. This design choice, conceptually closer to a traditional SERP despite its modern layout, demonstrates how UX and UI design can actively steer users toward more desirable behaviors, such as source verification and deeper exploration.
This design also addresses a critical concern raised by Kevin Roose of The New York Times: the potential for AI search engines to disintermediate content creators and publishers. If AI reliably summarizes information, what incentive remains for users to visit the original websites that produced that content? Andi’s design, by encouraging users to click through to sources, offers a potential model for preserving the vital ecosystem of online content creation.
The Imperative of Trustworthy AI: Shaping the Future of Search
The future of AI search hinges critically on the development and implementation of trustworthy AI. The question is not if AI will shape the future of search—as generative capabilities undeniably enhance user experience and expedite knowledge acquisition—but how it will do so. Key questions emerge:
- How can AI search engines be designed to ensure trustworthiness and explainability, rather than just convenience?
- What measures are necessary to prevent the erosion of human critical thinking and the uncritical acceptance of AI-generated information?
- How can the economic viability of content creators be maintained in an AI-summarized information landscape?
A Nature study highlighted conflicting user views on AI science search engines, with some researchers praising their utility and accuracy, while others expressed concerns about inconsistency and a lack of trust in retrieval performance. This underscores that trust is the central impediment to broader AI adoption in critical domains.
To cultivate trustworthy AI search engines, two primary areas of focus are essential:
-
Technical and Algorithmic Enhancements:
- Improved Explainability: Developing methods for LLMs to articulate their reasoning, source selection criteria, and confidence levels in their generated answers. Techniques like Retrieval-Augmented Generation (RAG) are crucial here, ensuring AI models reference external, authoritative data sources rather than relying solely on internal, potentially outdated or biased, training data. RAG, for instance, first retrieves relevant information from a knowledge base and then uses that information to generate a more accurate and attributable response, significantly reducing the risk of "AI hallucinations" – where models produce plausible but factually incorrect information.
- Bias Detection and Mitigation: Implementing robust mechanisms to identify and correct biases inherent in training data or model architecture, ensuring equitable and fair information presentation.
- Fact-Checking and Verification: Integrating automated or semi-automated fact-checking capabilities to validate generated summaries against multiple credible sources.
- Dynamic Source Attribution: Moving beyond simple links to provide more granular detail about which specific parts of which sources contributed to which parts of the generated answer.
-
User Experience and Ethical Design Principles:
- Transparency by Design: Integrating features that clearly indicate when information is AI-generated, how it was synthesized, and its potential limitations.
- Empowering User Scrutiny: Designing interfaces that encourage, rather than discourage, users to explore source materials, compare different perspectives, and critically evaluate the information provided. Andi’s approach, by keeping sources prominent, offers a model here.
- Educating Users: Developing educational resources or in-app guidance to help users understand the capabilities and limitations of AI search, fostering media literacy in the age of generative AI.
- User Control and Customization: Offering users options to adjust the level of summarization, the number of sources considered, or even the style of the answer, providing a greater sense of agency.
As new regulations, such as the EU AI Act, emerge to ensure safer and ethical uses of AI, the question of whether a "good" search experience—defined by convenience and speed—is also the "right" experience—defined by accuracy, trustworthiness, and intellectual integrity—becomes paramount. In a context where a significant portion of human decision-making is being delegated to LLMs, design efforts must prioritize accuracy, trustworthiness, and the comprehensiveness of search outputs. This necessitates far more than merely building a user-friendly conversational interface; it requires a deep commitment to ethical AI development and a thoughtful consideration of the long-term cognitive and societal impacts. The evolution of search is not just a technological race, but a critical juncture in how humanity interacts with, understands, and ultimately shapes its knowledge.
