: A Powerful New Web Accessibility Feature Demands Judicious Implementation")




The evolution of JavaScript from a simple scripting language for web pages to a robust platform for complex, large-scale applications has necessitated a fundamental shift in how code is organized and managed. At the heart of this transformation lies the concept of modules, a critical architectural decision that dictates an application’s maintainability, scalability, and performance. Before the advent of standardized module systems, JavaScript development, particularly for substantial projects, was a challenging endeavor fraught with global scope pollution and rampant variable name conflicts, where scripts haphazardly attached to the Document Object Model (DOM) could easily overwrite each other’s functionalities. Modern JavaScript modules address this by enabling developers to create private scopes for their code, explicitly define what parts are globally accessible, and establish clear boundaries between different components of a system, fundamentally altering the landscape of JavaScript development.
Historical Context and the Evolution of JavaScript Modularity
For many years, JavaScript lacked a native, standardized module system. Developers often resorted to various workarounds to manage code organization and prevent global namespace clashes. Common patterns included the Immediately Invoked Function Expression (IIFE), which created a private scope for a block of code, or manual object literal patterns to encapsulate related functionalities. While these techniques offered some relief, they were ad-hoc and lacked the formal structure needed for truly large-scale applications, especially as JavaScript began to expand beyond the browser environment.
The real impetus for a robust module system came with the rise of server-side JavaScript, particularly with the introduction of Node.js in 2009. Node.js applications, by their very nature, demanded a way to organize code into reusable units, similar to module systems found in languages like Python or Java. This demand led to the creation of CommonJS (CJS), the first widely adopted JavaScript module system. CommonJS was designed specifically for server-side environments, allowing developers to require() modules and export functionalities using module.exports. Its synchronous loading mechanism was well-suited for file system operations on a server but presented challenges for browser environments, where synchronous loading could block the main thread and degrade user experience.
Recognizing the growing need for a universal module system that could function seamlessly across both server and client, the ECMAScript standard body began working on a native solution. This effort culminated in ECMAScript Modules (ESM), standardized in ES2015 (also known as ES6). ESM introduced import and export statements, designed to be natively supported by browsers and to provide a more declarative and static approach to module management. The transition from CJS to ESM has been a significant journey, marked by years of interoperability challenges and the gradual adoption of ESM across the JavaScript ecosystem.
The Technical Divide: CommonJS vs. ECMAScript Modules
The fundamental difference between CommonJS and ECMAScript Modules lies in their design philosophies, specifically regarding how dependencies are handled and resolved. CommonJS, born out of the immediate needs of server-side development, offers a more dynamic and flexible approach. Its require() function is a runtime operation, meaning it can be called conditionally, inside if statements, or even within loops. The path to the module can also be dynamic, determined at runtime, as demonstrated by examples like const plugin = require(./plugins/$pluginName`). This flexibility made CJS highly adaptable but came with a significant trade-off.
Consider the following CommonJS example:
// CommonJS – require() is a function call, can appear anywhere
const module = require('./module')
// This is valid CommonJS – the dependency is conditional and unknowable until runtime
if (process.env.NODE_ENV === 'production')
const logger = require('./productionLogger')
// The path itself can be dynamic – no static tool can resolve this
const plugin = require(`./plugins/$pluginName`)In contrast, ECMAScript Modules prioritize static analyzability over runtime flexibility. The import statement in ESM is a declaration, not a function call, and must appear at the top level of a module. Conditional imports or dynamic paths, which are valid in CJS, are considered syntax errors in ESM.
Here’s how ESM handles similar scenarios:
// ESM – import is a declaration, not a function call
import formatDate from './formatters'
// Invalid ESM – imports must be at the top level, not conditional
if (process.env.NODE_ENV === 'production')
import logger from './productionLogger' // SyntaxError
// The path must be a static string – no dynamic resolution
import plugin from `./plugins/$pluginName` // SyntaxError: template literals are dynamic pathsThis deliberate design choice for ESM, while seemingly restrictive, yields substantial benefits for application performance and optimization. By mandating static import declarations, ESM allows static analysis tools, such as bundlers (e.g., Webpack, Rollup, Parcel, Vite), to determine the entire dependency graph of an application before runtime. This capability is crucial for techniques like tree-shaking, where unused code—often referred to as "dead code"—can be identified and eliminated from the final production bundle. For instance, if a module exports multiple functions but only one is imported and used, tree-shaking ensures that only the used function and its direct dependencies are included in the final output. In contrast, the dynamic nature of CommonJS imports makes it exceedingly difficult for static tools to confidently ascertain which modules are truly necessary, often leading to bundlers including more code by default, resulting in larger bundle sizes and slower application load times. The explicit design of ESM was a direct response to this limitation, leading to more efficient code delivery and improved user experiences.
Modules as Architectural Pillars
Beyond merely splitting code across files, JavaScript modules serve as fundamental building blocks for an application’s architecture. Every import and export statement is an architectural decision, shaping the relationships and boundaries between different parts of the system. This modularity facilitates the principle of separation of concerns, allowing developers to encapsulate related functionalities within distinct units. When managed thoughtfully, modules can enforce a clear flow of dependencies, which in turn reflects and supports a team’s organizational structure. Conversely, a poorly managed module system can quickly lead to an entangled codebase, making maintenance, feature development, and team collaboration arduous.

The concept of modules aligning with architectural principles is not new. Robert C. Martin, widely known as "Uncle Bob," is a prominent figure in software engineering and a proponent of Clean Architecture. This methodology, while sometimes debated as potential "over-engineering" for smaller projects, provides a robust framework for structuring applications that prioritize maintainability and testability. At its core is The Dependency Rule: "Nothing in an inner circle can know anything at all about something in an outer circle."
According to this rule, an application should be structured in concentric layers. The innermost layer typically contains the core Entities (business objects and rules), followed by Use Cases (application-specific business rules), then Interface Adapters (gateways, controllers, presenters), and finally the outermost layer of Frameworks and Drivers (databases, web frameworks, UI). Dependencies must always flow inward. This means the business logic (entities and use cases) should be entirely unaware of the specific technologies used to build the application (databases, UI frameworks). This insulation is paramount because business logic tends to be more stable than technological choices. When technology stacks inevitably evolve, the core business logic remains unaffected, drastically reducing refactoring efforts and enhancing the longevity of the application. JavaScript modules provide the concrete mechanism to enforce these architectural boundaries through explicit import/export relationships and directory structures.
Navigating the Module Graph: Tools and Best Practices
A powerful tool for understanding and maintaining a healthy application architecture is the module graph. This visual representation illustrates how different modules within a project depend on each other. Each time a module imports another, it adds an edge to this graph, dynamically shaping the project’s architectural footprint.
A healthy module graph typically exhibits a clear, unidirectional flow of dependencies, adhering to principles like the Dependency Rule. High-level modules depend on low-level ones, but never the reverse. This structure ensures that changes in lower-level, more volatile components do not ripple upwards to destabilize core business logic.
Conversely, an unhealthy module graph often displays complex, interwoven dependencies, characterized by circular dependencies or modules that exhibit excessive responsibilities. Circular dependencies occur when two or more modules directly or indirectly depend on each other (e.g., Module A imports B, and Module B imports A). This creates a tight, brittle coupling that makes modules difficult to reuse in isolation, challenging to test, and significantly increases the "blast radius" of any change—a modification in one module can unexpectedly break others in the cycle.
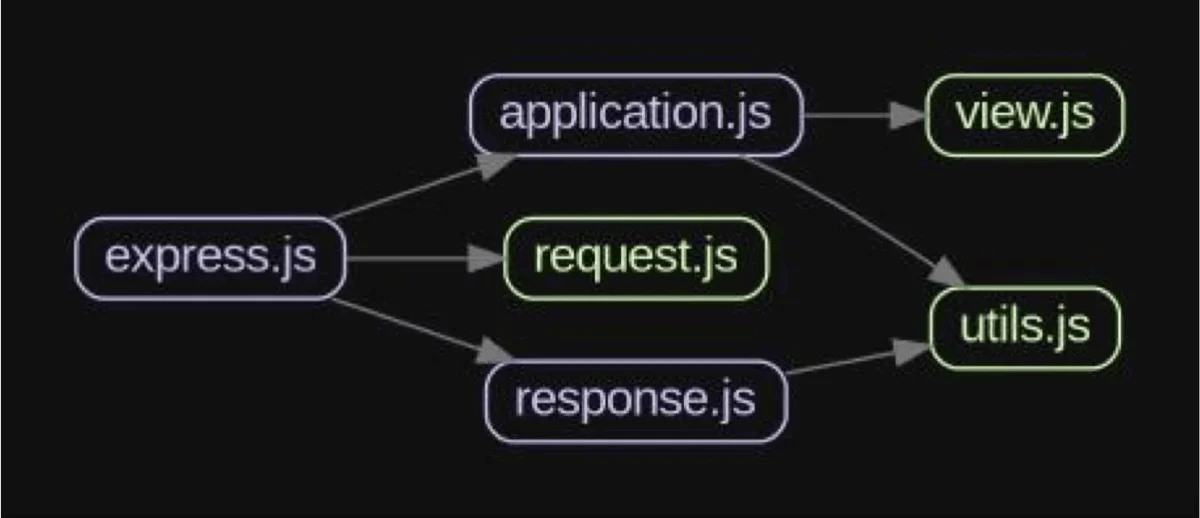
Consider a scenario where a utils.js module becomes a catch-all for various unrelated helper functions. If utils.js starts importing from several other application modules (e.g., request.js, view.js) while also being imported by many, it becomes a central point of failure. Any issue in utils.js could affect a large portion of the application, and its high number of incoming and outgoing dependencies makes it difficult to reason about and test. This violates the Single Responsibility Principle (SRP), which advocates that a module should have only one reason to change. By breaking down such an overloaded utils.js into smaller, cohesive, and focused modules, developers can significantly reduce coupling, improve testability, and enhance overall stability.
Fortunately, several tools assist developers in visualizing and managing their module graphs. Madge is a popular utility that generates visual representations of module dependencies, making it easy to spot problematic patterns like circular dependencies. Dependency Cruiser takes this a step further, not only visualizing dependencies but also allowing developers to define and enforce architectural rules. With Dependency Cruiser, teams can specify which layers or directories are permitted to import from others, effectively codifying the Dependency Rule and preventing accidental architectural regressions. By actively monitoring and refining their module graphs, teams can optimize build times, mitigate architectural debt, and ensure their applications remain robust and scalable.
Performance Trade-offs: The Barrel File Dilemma
One common pattern that has emerged in JavaScript module usage, particularly in larger projects, is the barrel file. A barrel file, typically named index.js or index.ts, serves as a centralized point to re-export components from multiple other files within a directory. This approach aims to simplify imports, making code cleaner and ostensibly more readable.
For example, instead of importing individual functions from separate files:
// somewhere else in the app
import login from '@/features/auth/login';
import register from '@/features/auth/register';A barrel file in the auth directory (auth/index.ts) would consolidate these exports:
// auth/index.ts
export * from './login';
export * from './register';Allowing for a cleaner, single-line import:
// somewhere else in the app
import login, register from '@/features/auth';While barrel files offer undeniable convenience and improve code readability for small to medium-sized projects, they introduce significant performance drawbacks in larger applications, particularly concerning build times and bundle sizes. The primary issue stems from how modern JavaScript bundlers perform tree-shaking. Even if only a single export from a barrel file is ultimately used in a consumer module, the bundler might still process the entire barrel file and all its underlying dependencies to determine what could be exported. This can lead to less effective tree-shaking, resulting in larger JavaScript bundles than necessary, and consequently, slower application load times.

Real-world data supports this concern. Atlassian, for instance, famously reported achieving 75% faster builds and a measurable reduction in JavaScript bundle size for their Jira application’s front-end simply by removing barrel files. Similarly, a case study on the MSW (Mock Service Worker) library project detailed the negative effects barrel files had on their build performance. For smaller projects where build times are negligible and bundle sizes are inherently small, the readability benefits of barrel files might outweigh their performance costs. However, for enterprise-scale applications, the impact on developer productivity due to prolonged build times and the degradation of user experience from larger bundles makes a compelling argument against their widespread use. A judicious approach involves using barrel files only when the exports are truly co-dependent and likely to be used together, or for very specific, small utility groupings.
Managing Interdependencies: The Challenge of Coupling
Coupling describes the degree of interdependence between different components within a system. While some level of coupling is inherent and necessary for an application to function, certain types of coupling can severely hinder maintainability and scalability. Developers must actively strive to minimize tight coupling and eliminate implicit coupling.
Tight coupling occurs when one module is heavily reliant on the internal implementation details of another module, rather than just its public interface. This creates a fragile relationship where changes to the "dependency" module’s internal logic necessitate corresponding changes in the "dependent" module. This phenomenon is often termed change amplification, where a seemingly minor adjustment in one area cascades into required modifications across numerous other modules. Such tight interdependencies make refactoring a perilous task, increasing the risk of introducing new bugs and significantly slowing down development cycles. Strategies to mitigate tight coupling include using dependency injection, designing clear interfaces or abstractions, and favoring event-driven architectures where modules communicate through explicit events rather than direct calls to internal methods.
Implicit coupling, on the other hand, is more insidious because it represents a hidden or undocumented dependency between modules. This often arises from patterns like global singletons, shared mutable state, or modules that produce side effects without explicit declarations. Implicit coupling leads to unpredictable behavior, makes debugging incredibly difficult, and can also lead to inaccurate tree-shaking, as static analysis tools struggle to identify these hidden linkages. Addressing implicit coupling involves embracing principles like pure functions (functions that produce the same output for the same input and have no side effects), immutability (preventing direct modification of data), and explicit state management patterns that make data flow transparent. The goal is to achieve loose coupling (modules interact through stable, well-defined interfaces) and high cohesion (modules encapsulate closely related functionalities), which are hallmarks of a robust and adaptable software system.
Organizational Structure Reflected in Code: Conway’s Law in Practice
The architecture of a software system is not solely a technical concern; it is profoundly influenced by the human organization that creates it. This fundamental truth is encapsulated by Conway’s Law, a principle articulated by computer programmer Melvin Conway in 1967: "Any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization’s communication structure."
This law suggests that the way teams are organized and how they communicate will inevitably be mirrored in the module boundaries and overall architecture of the software they build. When different modules of a large-scale application are assigned to distinct teams, these team boundaries often translate directly into module boundaries within the codebase. The nature of communication and code ownership (e.g., weak, strong, or collective) significantly impacts the resulting architecture:
| Good Communication | Poor Communication | |
|---|---|---|
| Weak Code Ownership | Architecture may still emerge, but boundaries remain unclear | Fragmented, inconsistent architecture |
| Strong Code Ownership | Clear, cohesive architecture aligned with ownership boundaries | Disconnected modules; integration mismatches |
| Collective Code Ownership | Highly collaborative, integrated architecture | Blurred boundaries; architectural drift |
For instance, an organization with strong, independent teams, each owning a specific set of services or features, is likely to produce a microservices architecture with well-defined module boundaries that align with team responsibilities. Conversely, if communication between teams is poor, even if they are ostensibly working on related modules, the resulting system may exhibit integration mismatches and inconsistent architectural patterns. This principle underscores that effective software architecture requires not only technical prowess but also thoughtful organizational design and clear communication channels. A critical implication is that modules that frequently evolve together should ideally share the same boundary or be owned by the same team, as their shared evolution is a strong indicator that they form a cohesive functional unit.
Conclusion and Forward Outlook
Structuring a large JavaScript project extends far beyond mere file and folder organization; it is a strategic architectural undertaking. It involves the deliberate creation of boundaries through modules, thoughtfully coupling them to construct a functional, performant, and maintainable system. By proactively designing your project’s architecture, rather than letting it evolve haphazardly, developers can circumvent the significant hassles associated with extensive refactoring, enabling their projects to scale gracefully and adapt to future requirements.
For teams managing existing projects, a practical first step is to gain visibility into their current module graph. Tools like Madge or Dependency Cruiser can be invaluable for this purpose. By visualizing the actual dependency flow, developers can identify architectural anomalies such as circular dependencies, overly complex modules, or unintended cross-layer imports. The subsequent actions involve enforcing stricter boundaries, systematically breaking circular chains, refactoring modules to adhere to principles like SRP, and extracting granular utilities. This process doesn’t necessitate a complete overhaul; incremental changes can yield substantial long-term benefits. The ongoing evolution of JavaScript, including advancements in bundler technology and stricter language features like ESM, continues to emphasize the importance of deliberate module design. The ultimate question for every development team remains: Are you letting your module structure happen to you, or are you actively designing it for success?
